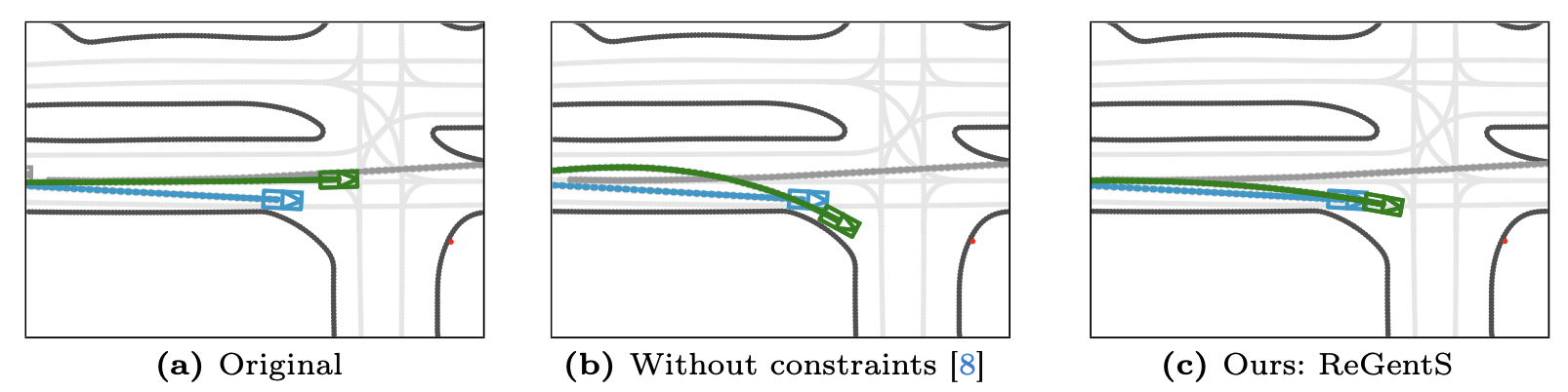
Hi, I’m Yuan YIN 银元
AI Researcher at Valeo.ai
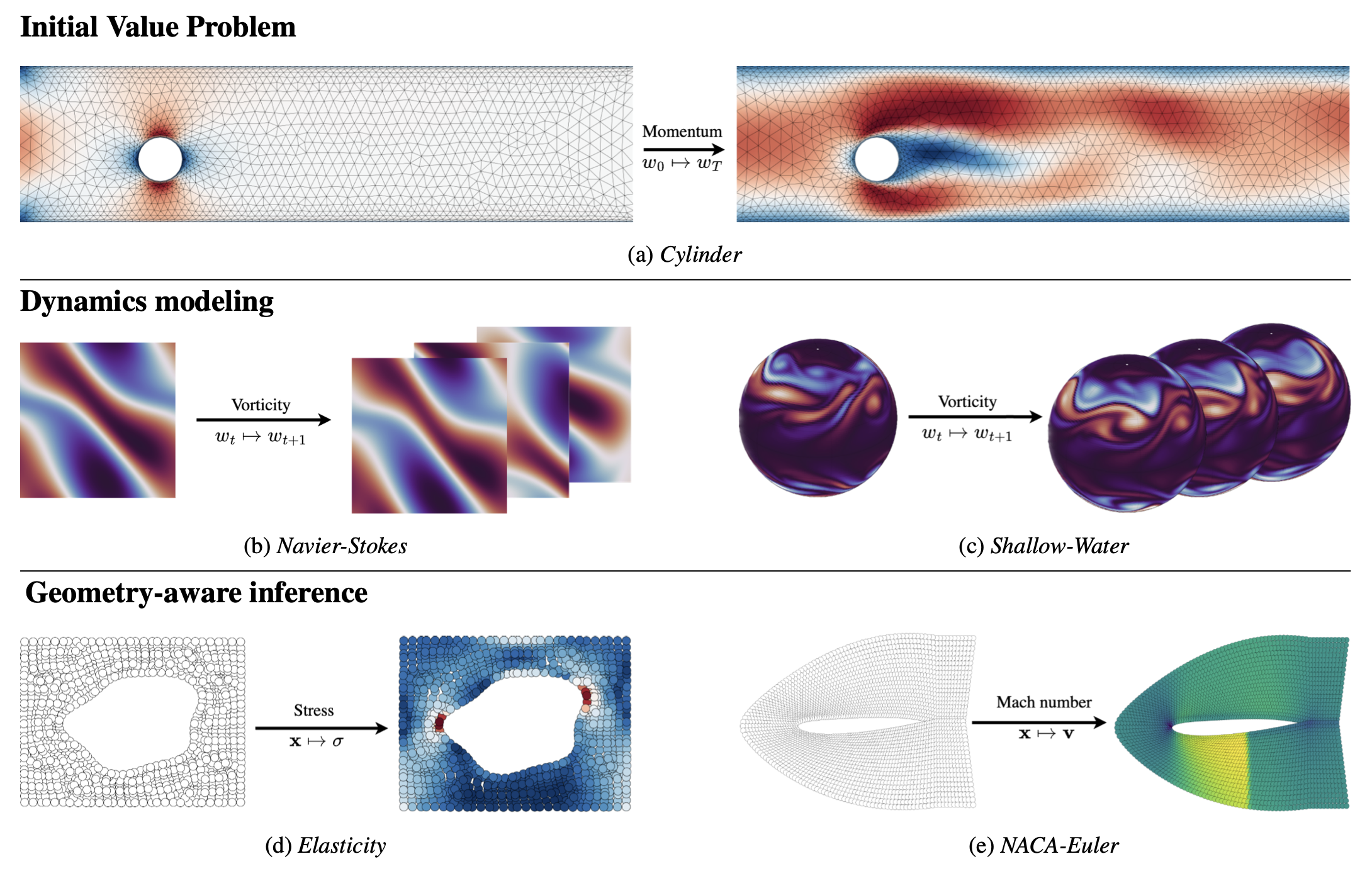
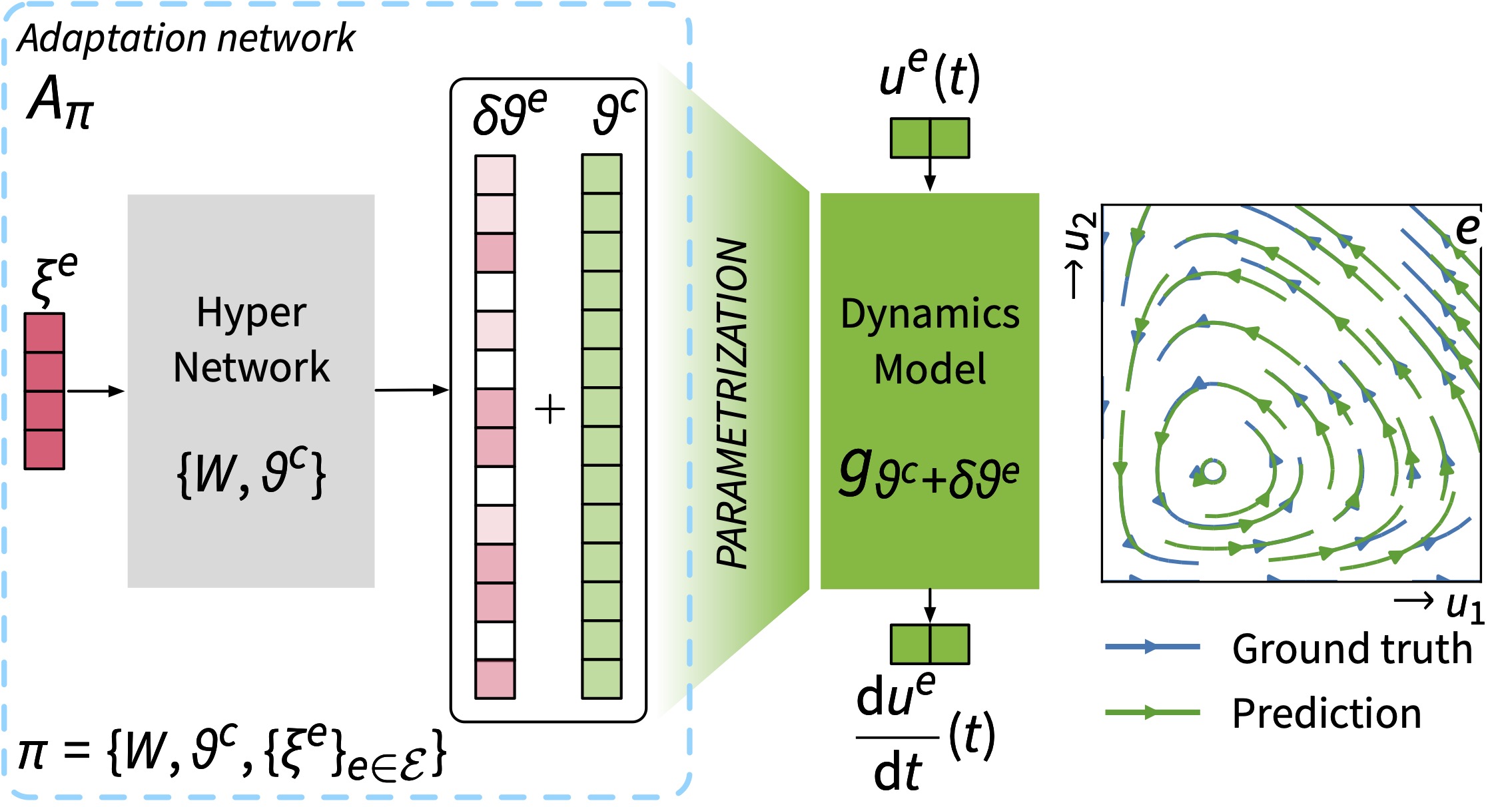
My research focuses on machine learning and deep learning for spatiotemporal sequence modeling, simulation, prediction, and analysis of complex behaviors. I also explore methods to extend the generalization of data-driven models, particularly through model adaptation.
I defended my PhD in June 2023 at Sorbonne Université, under the supervision of Prof. Patrick Gallinari and Assoc. Prof. Nicolas Baskiotis. Before that, I obtained my BSc in Computer Science from Beihang University, followed by my MSc in Computer Science from Université Paris Cité and Sorbonne Université.

Latest update
Selected publications
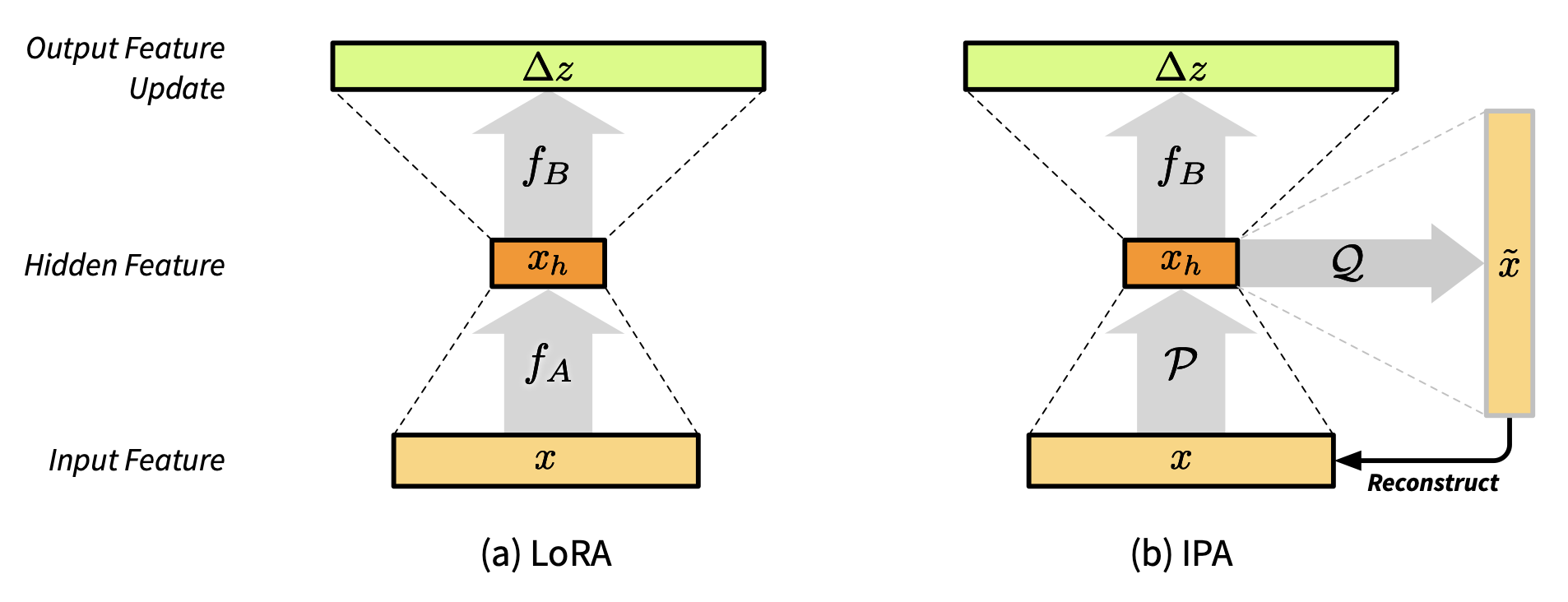
- IPA: An Information-Reconstructive Input Projection Framework for Efficient Foundation Model AdaptationTransactions on Machine Learning Research, Sep 2025
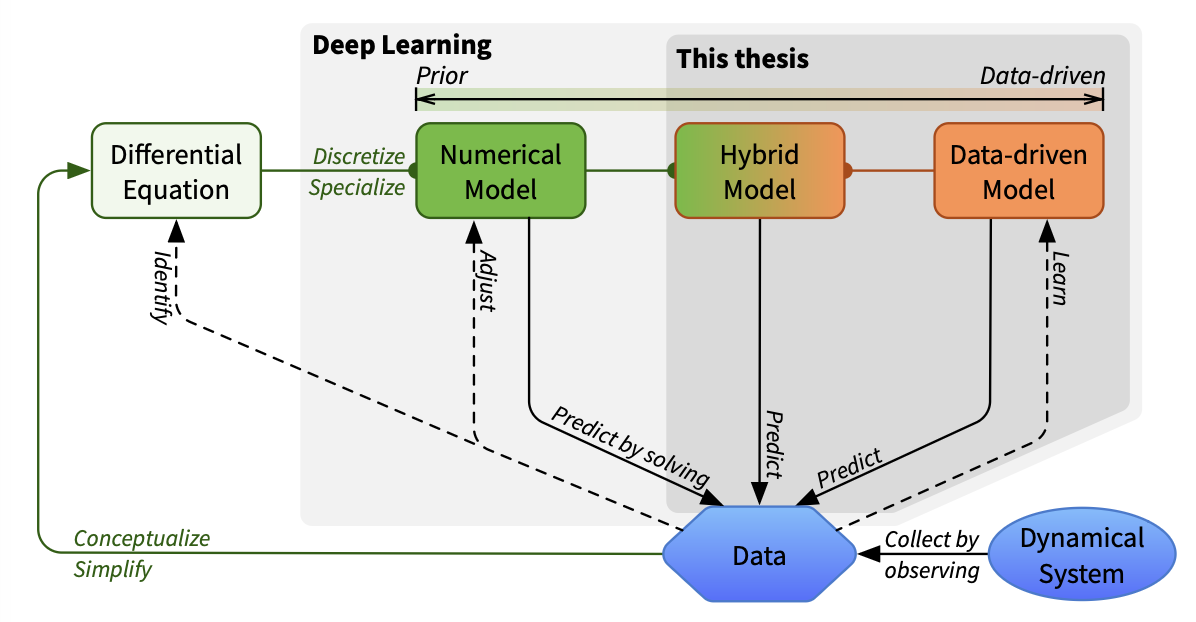
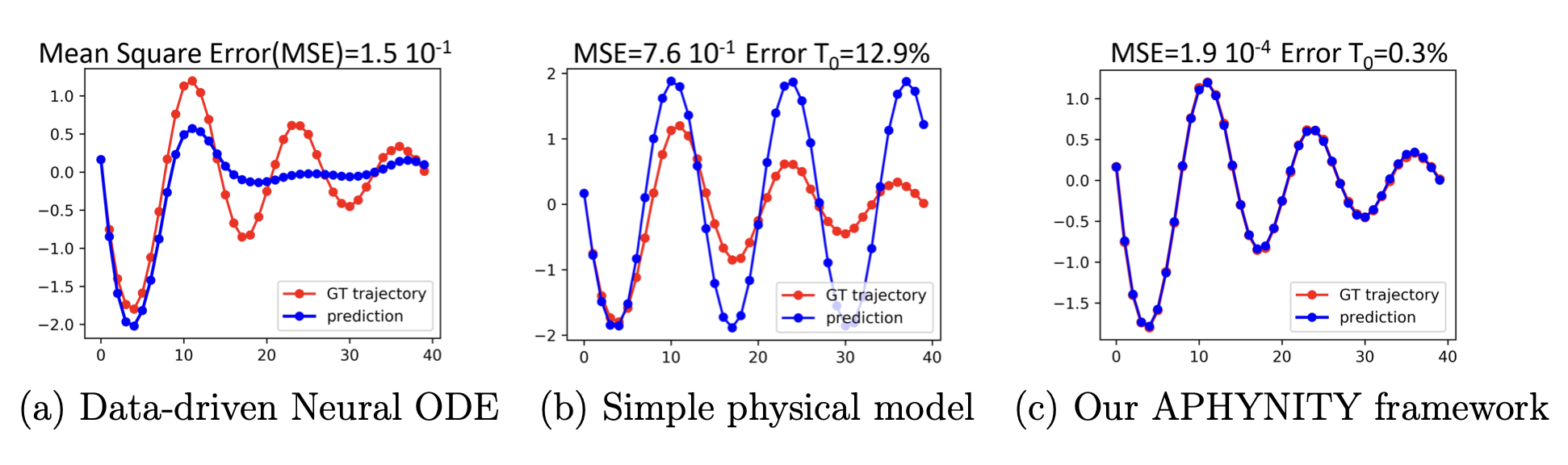
- Physics-Aware Deep Learning and Dynamical Systems: Hybrid Modeling and Generalization. (Apprentissage profond pour la physique et les systèmes dynamiques : modélisation hybride et généralisation)Sorbonne University, Paris, France, Jun 2023